12 years ago, Muhuratam started as a very simple Android app to calculate Choghadiya. The first version did not have any grand architecture. It was just solving a small problem I had seen at home: people wanted to know whether the current time was good enough to start something, without opening a calendar and doing mental math.
With the advent of agentic engineering, I've spent a few weekends re-creating Muhuratam which has become a lot more than just a choghadiya app. The web app now has Panchang, Choghadiya, Rahu Kaal, Brahma Muhurat, birth charts, festivals, Griha Pravesh Muhurat, etc., all dynamically calcualted based on date and location with multilingual content. More functionality and possibilities need a good search within the app for discoverability.
It wouldn't be very difficult to route a "panchang mumbai" query to /panchang/mumbai, but that's not how users always search.
They search for things like:
- "aaj ka rahu kaal pune"
- "diwali choghadiya"
- "tritiya panchang"
- "kal ka panchang mumbai"
- "griha pravesh muhurat ahmedabad 2026"
- "holi dahan ki taareekh batao"
These queries are a little difficult for a normal keyword search because the intent is hidden behind language, transliteration, domain terms, date logic, and missing context.
There are complex engineering ways to solve this problem. We could have built a rule-based multilingual search system with curated keyword/alias dictionaries for intents, festivals, cities, dates, and transliterations, mapped deterministically to known site URLs.
Guess which new kid in the town understands intents in all possible languages and domains(including vedic astrology)? LLMs to the rescue! It was a great opportunity to take advantage of all the training received by the latest large language models.
So, we create a chatbot?
Most AI search implementations eventually become chatbots. That is not necessarily bad, but it was not the right fit for Muhuratam.
A chatbot is verbose by default. If you ask "Rahu Kaal in Pune today", it will happily explain what Rahu Kaal is, why it matters, how to calculate it, and then maybe give you an answer. That is useful in some products, but search should be more direct.
Also, chatbots are too easy to distract. You start with Panchang and then trick them into solving homework, writing poetry, or giving generic spiritual advice. I did not want to build a general-purpose assistant. I wanted to return structured search results that open the right Muhuratam pages.

So the contract is intentionally boring:
{
"results": [
{
"url": "/panchang/mumbai?date=2026-04-27",
"title": "Panchang - Mumbai",
"type": "panchang",
"snippet": "Day panchang overview for Mumbai",
"score": 0.95
}
]
}
No long answers. No external links. No markdown. No philosophical detours. Just search results.
That is why LangGraph ended up being a good fit. Search is not one prompt. It is a sequence: normalize the request, infer intent, validate city, generate safe URLs, give tools to the model work with, then sanitize everything before it reaches the user.
The first thought: use n8n
My first implementation was an n8n workflow. It was convenient because n8n already gives you webhooks, HTTP calls, model nodes, and a nice visual way to debug the flow.
For a prototype, this was great.
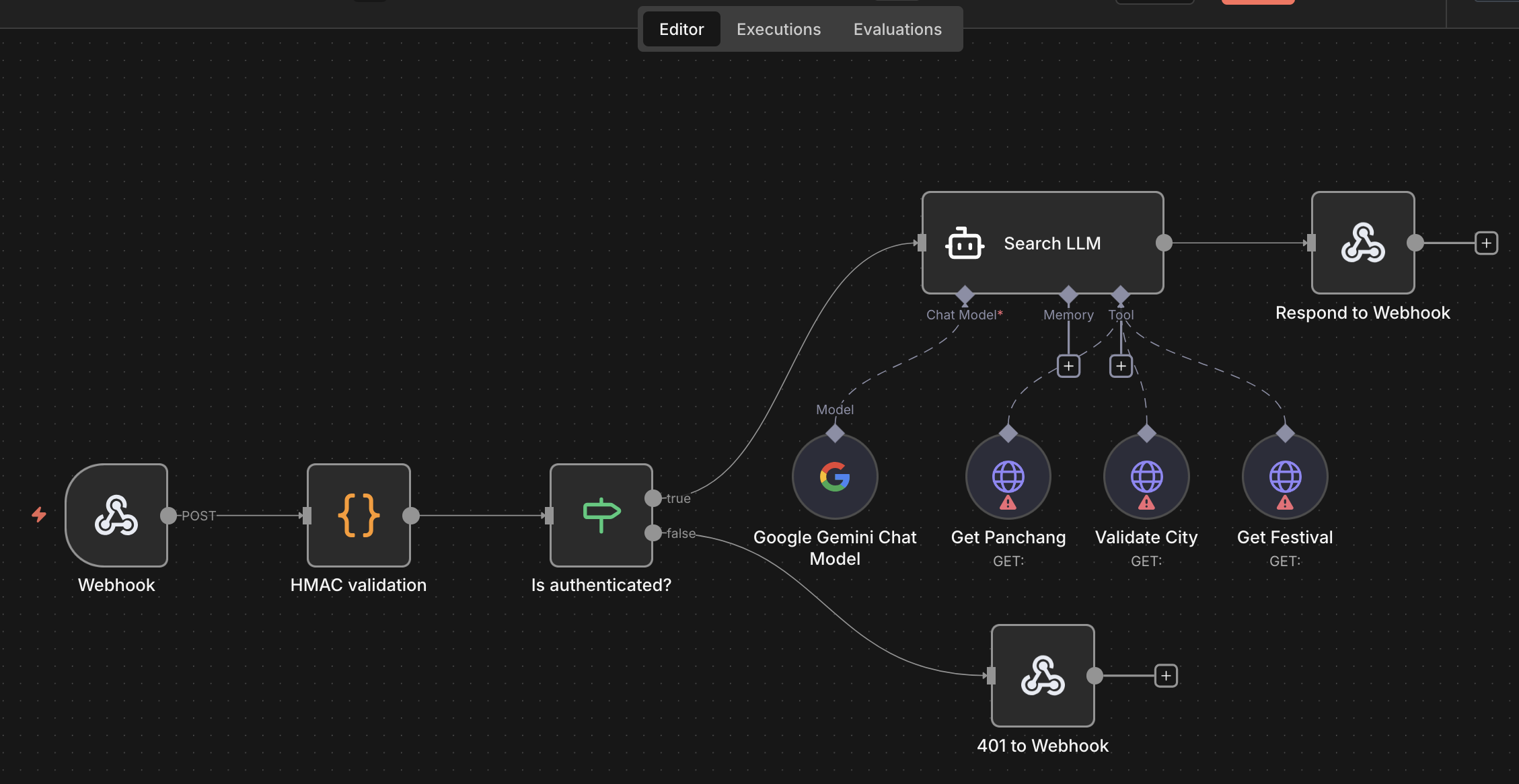
But then, I looked at the pricing. The paid hobby account gives 2,500 workflow executions per month. That sounds like a decent number until you put it behind a search box. Even if a small percentage of users try it, search can burn through that quota very quickly. I have been spending a lot more on my side projects these days and this could soon go way over budget.
I considered deploying n8n myself on Railway. But at that point I was adding a whole workflow platform just to run one fairly specific workflow. I would need to manage the instance, environment, upgrades, storage, and whatever other small operational surprises come with self-hosting.
The more I thought about it, the more it felt like I did not need n8n. I needed a small internal service with a few predictable steps. With a prompt, a python service using FastAPI, LangGraph, etc. was created in the same railway project where I have been moving muhuratam backend APIs (story for another day).
This is less glamorous than a visual workflow, but much easier to reason about and much cheaper to run.
You could have just integrated any LLM API!
Yes, that could have been one way to do this, but LangGraph made sense because this was not a pure "send prompt, get answer" problem.
I needed a few stages with clear boundaries:
- Validate and normalize the request.
- Extract language, city, date, festival, and page intent.
- Generate deterministic candidate URLs from the site knowledge base.
- Call internal tools only when needed, such as city search or Panchang.
- Let the LLM enrich results, but not own the full response.
- Sanitize the output before returning it.
This workflow is small today, but it benefits from being explicit. I can test each part, log each part, and fail-soft at each part. If the model is unavailable, the deterministic URL generation still works. If city validation fails, the request can still return city-less fallback pages. If the model gives me weird output, the final sanitizer drops it.
That is especially useful for multi-lingual search because language handling is not just translation. A Hindi query can arrive in Devanagari or Hinglish. Gujarati can arrive with a lang=gu app context (or may be not). The user may ask in Hindi but still need both an English canonical URL and a Hindi URL variant. LangGraph gives me a simple place to keep those steps separate instead of hiding everything inside one large prompt.
Let us look at the flow
There are three pieces involved now:
- The Next.js web app hosted on Vercel.
- The NestJS backend API hosted on Railway.
- The Python LangGraph service hosted in the same Railway project.
The web app calls its own /api/app-search route. That route validates the query, resolves the selected city if available, and calls Muhuratam API.
The NestJS API has a /api/v1/search endpoint. It does two things in parallel:
- calls the AI search service
- builds deterministic fallback results
If the AI service works, the API merges AI results with fallback results. If the AI service times out or fails, the user still gets deterministic results.
That fallback is very important. I do not want a model outage to make search useless.
Inside Search service, the LangGraph workflow is currently simple:
- Validate and normalize input.
- Extract intent and generate deterministic URL candidates.
- Optionally ask the LLM to enrich ranking, titles, snippets, and add a few missed URLs.
- Rank/localize results.
- Sanitize the final output.
The important point is that the LLM is not the only brain in the system. LangGraph is the control flow, deterministic routing is the baseline, backend APIs are the trusted tools, and the LLM is an enrichment layer.
What did we learn?
Building this hybrid search system taught me a few valuable lessons about mixing deterministic software with LLMs:
- Vector databases aren't always necessary: Since Muhuratam's search space maps to known routes, a simple JSON knowledge base was enough. The LLM translates user queries to known paths rather than doing semantic document retrieval.
- Keep prompts focused: LLM cost is directly dependent on token count. Initially, I tried passing all supported cities to the LLM. This meant ~3000 input tokens per request. Moving city validation to a deterministic API to be used as a tool reduced it to less 1000 tokens.
- Let AI handle messy inputs: The LLM shines at understanding transliteration, Hinglish, informal date references ("aaj", "kal"), and synonyms without needing endless manual mapping rules.
- Trust, but verify (strictly): Initially the LLM started halucinating URLs. I had to put in checks on UI to make sure we do not show unknown paths in the search results. The model is not expected to return unvalidated URLs or external links. If the LLM fails, times out, or returns mixed-language content, the system safely falls back to deterministic results.
- Start small to control costs: AI search is currently mobile-only for Muhuratam. The smaller user base mitigates the risk of high token costs from web bots. After trying multiple models, I settled on the Gemini 2.5 Flash for now. Will have to keep monitoring the results to see if a different one would be best value for money.
- Provider quirks exist: Different models handle structured output differently (e.g., returning JSON as plain text). Handling these edge cases and accepting higher latency are real trade-offs compared to traditional search.
- Know when to use this architecture: This route-aware LangGraph approach is ideal if your search space is structured, multilingual intent is critical, and you want to avoid the cost of full RAG. However, if you are searching millions of unstructured documents, PDFs, or enterprise knowledge bases, traditional vector search and hybrid retrieval might be a better fit.
- Latency is the biggest challenge: This architecture works for hobby projects like Muhuratam but real world applications need faster search. Right now a search on Muhuratam takes anywhere from 10 to 15 seconds. There are multiple ways to improve this. Let us keep that for a future post.
Future roadmap
There are a few things I want to improve next.
- I want to make festival/date resolution stronger. Queries like "Choghadiya for Diwali" should resolve Diwali's date for the selected city/year and return a date-aware Choghadiya link.
- I want better evaluation. Big companies use automated evaluation systems for search quality. I do not need that scale, but I do need a small golden set of queries in English, Hindi, Gujarati, and Hinglish. Every change to prompts, models, or route logic should be tested against that set.
- I want better latency. This may mean caching more aggressively, reducing prompt size further, using model calls only for low-confidence queries, or streaming partial deterministic results before enrichment.
- I want to improve observability. The service already logs latency, model usage, tool time, cache hits, intent, city, date, and empty result reasons. Over time, this should tell me where users are failing and which queries deserve first-class deterministic support.
- I may eventually bring some version of this to web, but only after I have stronger rate limiting, abuse protection, and confidence that the feature is worth the compute.
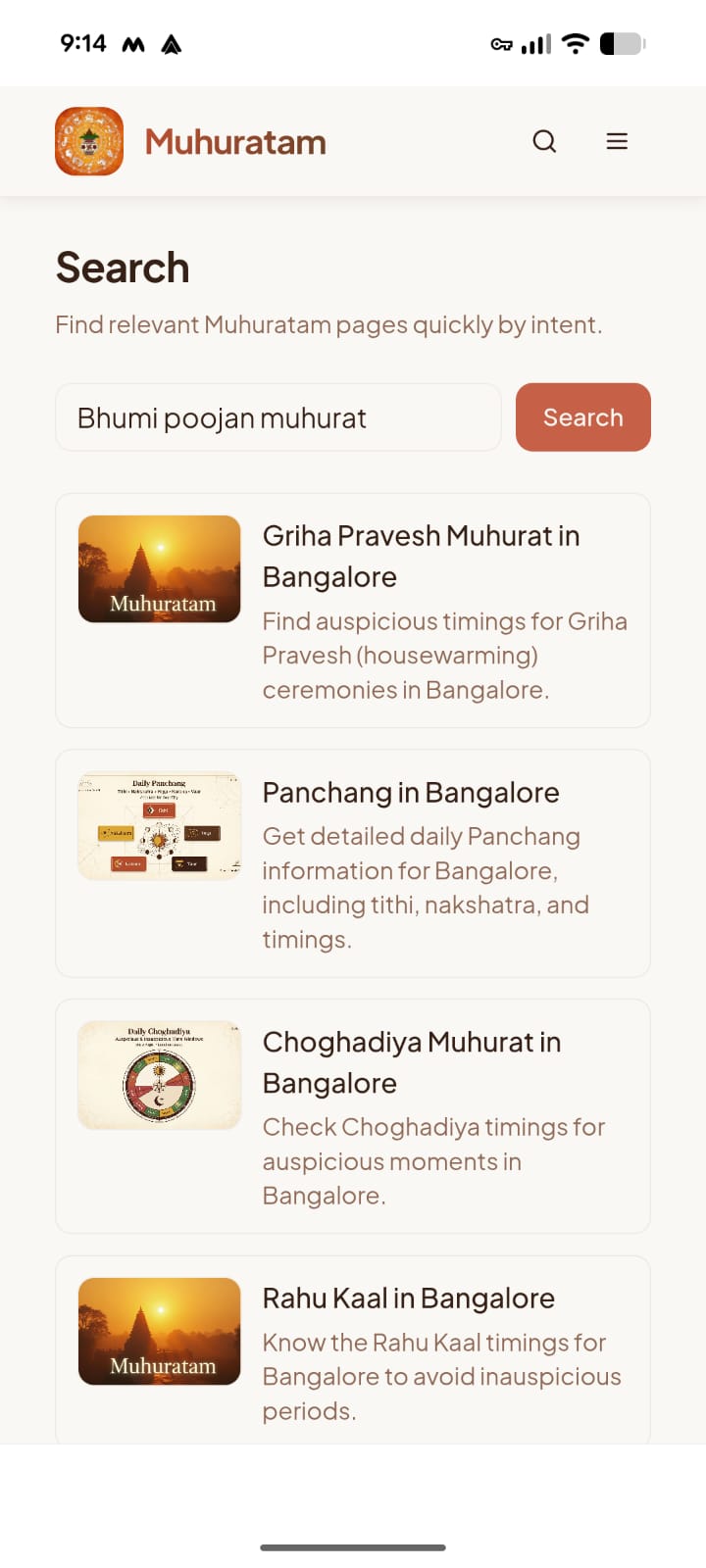
- Search queries are already giving some good suggestion what users would like to see on the App. For example, there have been multiple searches on "Bhumi Poojan Muhurat" which is not supported right now. In ideal case, search queries, cities, etc. would flow through an ETL pipeline into my existing CPO and TPM agent which would then create future roadmap.
Final thoughts
The more I build with AI, the more I feel the useful pattern is not "replace everything with an LLM".
It is to let software do what software is good at, and let the model help with the parts that are fuzzy.
For Muhuratam search, software is good at validating cities, generating URLs, calculating Panchang, checking allowed paths, and enforcing language rules. LangGraph gives these steps a clear workflow. The model is good at understanding what the user probably meant when they typed a messy multi-lingual query.
That combination is much more useful than a chatbot.
It is also a nice reminder of something I have learned repeatedly from side projects: the best architecture is not the most impressive one. It is the one that solves the current problem without creating five new ones.
If you'd like to try it out then please download Android or iOS app and let me know the feedback.
Thoughts, questions, critique welcome.
Happy Building!